Quantitative research uses numerical data, such as measurements, survey responses, and experiment results, to explore a research question. Quantitative data are analyzed with statistics to test a theory or hypothesis.
Quantitative research methods can be applied to find patterns, identify causal relationships, and model real-world processes. Many fields, including biology, chemistry, economics, physics, and psychology, use quantitative methods.
Not all phenomena can be expressed using numbers—in such cases, qualitative research methods should be used instead. Qualitative and quantitative methods can also be combined in mixed methods research.
Qualitative research uses narrative, nonnumerical data to explore research questions. Nonnumerical data may include text, photos, or videos. Qualitative research is useful for gaining deep insight into a topic or generating new ideas and theories.
Qualitative research can be conducted on its own or in combination with quantitative research methods (which use numerical data). The combination of qualitative and quantitative approaches is called mixed methods research.
When conducting research, especially research that involves human participants, it’s important to adhere to research ethics. Research ethics are principles that provide a framework for researchers to distinguish “right” from “wrong.” They guide scientists throughout the research process to maximize the benefits of their work while minimizing the potential for harm.
Research ethics principles vary between countries and organizations but share common goals:
Protect the rights and privacy of research participants
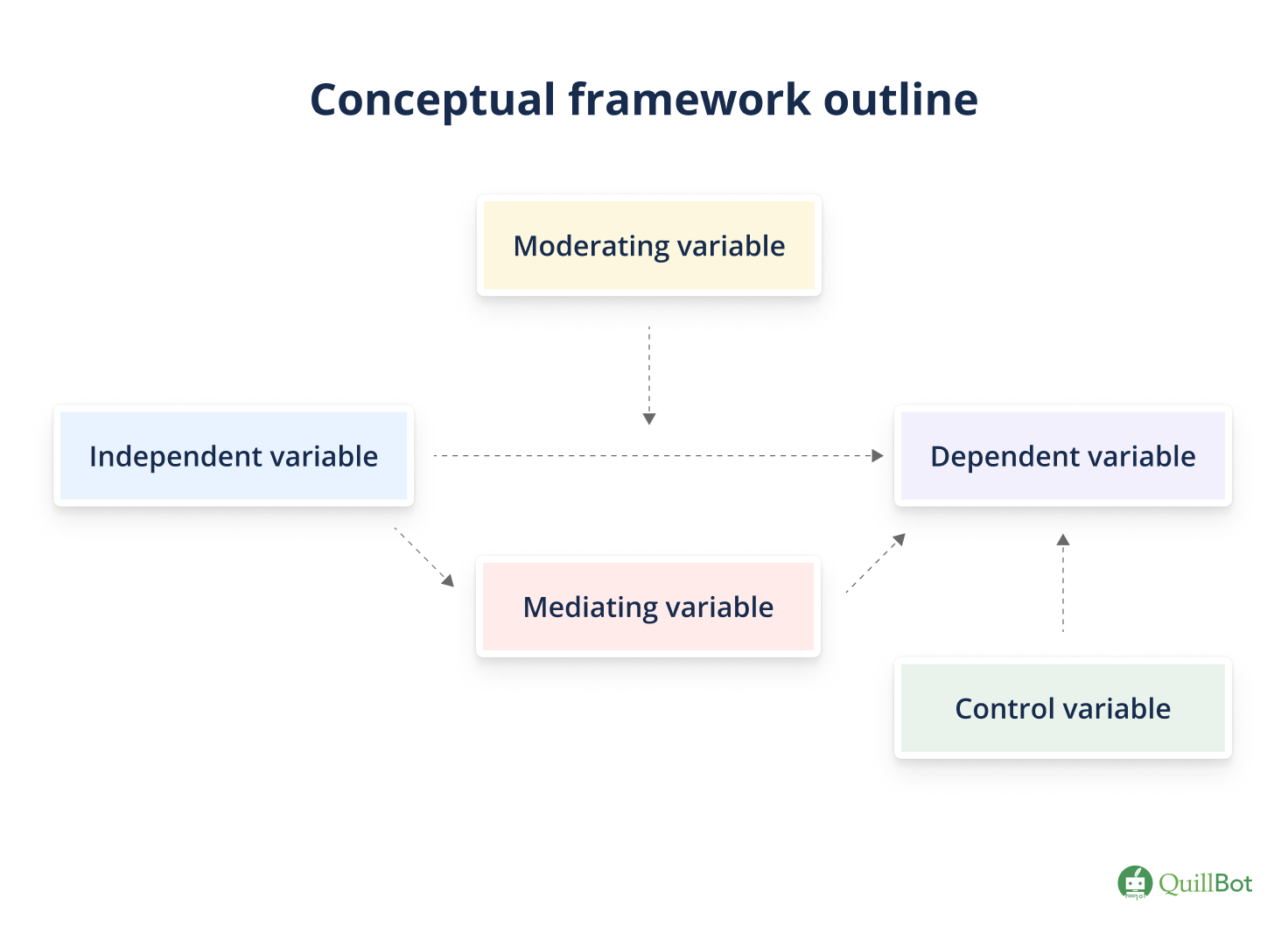
A conceptual framework identifies different variables in a study and illustrates the relationship between them.
Variables are quantities, traits, or conditions that can take on different values. An experiment tests the cause-and-effect relationship between an independent variable and a dependent variable, but it may also contain control variables, mediator variables, moderator variables, and confounding variables.
In an experiment, a researcher tests a hypothesis by manipulating an independent variable and measuring its impact on a dependent variable. A variable is any property that can take on different values (e.g., height, temperature, GPA).
Experiments test cause-and-effect relationships:
Independent variables are the cause—the thing that is changed by the researcher.
Dependent variables are the effect—the thing that changes in response to manipulations of the independent variable.
In other words, you systematically vary the independent variable and measure the resulting changes in the dependent variable.
Independent and dependent variables
Independent variable
Dependent variable
Manipulated by the researcher
Measured by the researcher
Acts as the cause
Represents the effect
The “if” part of a hypothesis (i.e., “if I change [this variable]…”)
The “then” part of a hypothesis (i.e., “… then this variable should change.”)
Plotted on the x-axis of a graph
Plotted on the y-axis of a graph
Occurs earlier in time in an experiment
Occurs later in time in an experiment
Also called an input, predictor variable, explanatory variable, manipulated variable, or treatment variable
Also called an output, predicted variable, explained variable, measured variable, or outcome
When choosing how to measure something, you must ensure that your method is both reliable and valid. Reliability concerns how consistent a test is, and validity (or test validity) concerns its accuracy.
Reliability and validity are especially important in research areas like psychology that study constructs. A construct is a variable that cannot be directly measured, such as happiness or anxiety.
Researchers must carefully operationalize, or define how they will measure, constructs and design instruments to properly capture them. Ensuring the reliability and validity of these instruments is a necessary component of meaningful and reproducible research.
Reliability vs validity examples
Reliability
Validity
Definition
Whether a test yields the same results when repeated.
How well a test actually measures what it’s supposed to.
Key question
Is this measurement consistent?
Is this measurement accurate?
Relationship
A test can be reliable but not valid; you might get consistent results but be measuring the wrong thing.
A valid test must be reliable; if you are measuring something accurately, your results should be consistent.
Example of failure
A bathroom scale produces a different result each time you step on it, even though your weight hasn’t changed. The scale is not reliable or valid.
A bathroom scale gives consistent readings (it’s reliable) but all measurements are off by 5 pounds (it’s not valid).
Validity (more specifically, test validity) is whether a test or instrument is actually measuring the thing it’s supposed to. Validity is especially important in fields like psychology that involve the study of constructs (phenomena that cannot be directly measured).
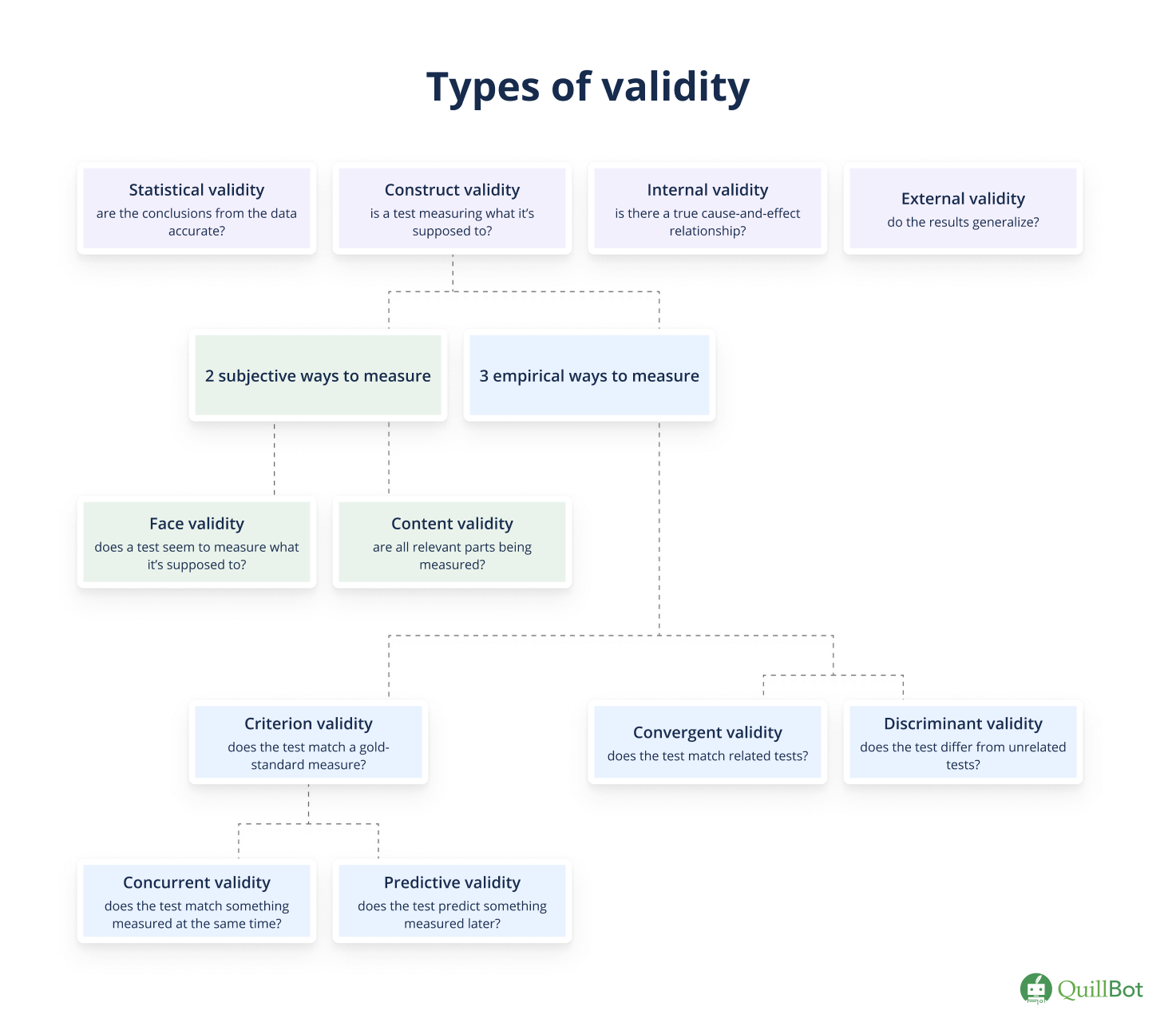
There are various types of test (or measurement) validity that provide evidence of the overall validity of a measure. Different types of validity in research include construct validity, face validity, content validity, criterion validity, convergent validity, and discriminant validity.
Test validity is the primary focus of this article. When conducting research, you might also want to consider experimental validity, which concerns research and experiment design more broadly. Internal validity, external validity, and ecological validity relate to the quality of a study and the applicability of its results to the real world.
TipA generative AI tool, like QuillBot’s AI Chat, can help you analyze potential problems with validity in your own and others’ research. Just be sure to supplement that information with expert opinions and your own judgment.
Discriminant validity (or divergent validity) captures whether a test designed to measure a specific construct yields results different from tests designed to measure theoretically unrelated constructs.
Discriminant validity is evaluated alongside convergent validity, which assesses whether a test produces results similar to tests that measure related constructs. Together, convergent and discriminant validity provide complementary evidence of construct validity—whether a test measures the construct it’s supposed to.
Discriminant validity exampleSuppose you want to study language development in infants. You therefore design a protocol that measures vocabulary recognition.
To ensure that your test is sensitive to this trait and not others, you compare infants’ scores on your test to their scores on a fine motor skills test. You do not expect to observe a relationship between vocabulary recognition and fine motor skills.
A low correlation between infant scores on these tests supports the discriminant validity of your protocol.
Convergent validity is one way to demonstrate the validity of a test—whether it’s measuring the thing it’s supposed to. Specifically, convergent validity evaluates whether a test matches other tests of similar constructs.
If two tests are measuring the same thing, their results should be strongly correlated. This strong correlation indicates convergent validity, which in turn provides evidence of construct validity.
Convergent validity exampleA psychologist wants to create an intake form to quickly evaluate distress tolerance in their patients.
They compare the results of their form to a survey that measures emotional regulation, as they expect this construct to closely relate to distress tolerance.
A high correlation between their form and the existing survey indicates convergent validity.
TipWhen creating any type of survey or questionnaire, accuracy is important. Make sure your questions and answers are clear and error-free with QuillBot’s Grammar Checker.
Construct validity refers to how well a test or instrument measures the theoretical concept it’s supposed to. Demonstrating construct validity is central to establishing the overall validity of a method.
Construct validity tells researchers whether a measurement instrument properly reflects a construct—a phenomenon that cannot be directly measured, such as happiness or stress. Such constructs are common in psychology and other social sciences.
Construct validity exampleA team of researchers would like to measure cell phone addiction in teenagers. They develop a questionnaire that asks teenagers about their phone-related attitudes and behaviors. To gauge whether their questionnaire is actually measuring phone addiction (i.e., whether it has construct validity), they perform the following assessments:
The team evaluates face validity by reading through their questionnaire and asking themselves whether each question seems related to cell phone use.
The team measures criterion validity by comparing participants’ questionnaire results with their average daily screen time. They expect to see a high correlation between these two variables.
Finally, the researchers examine divergent validity by comparing their questionnaire results to those of a standard creativity test. Because the constructs of phone addiction and creativity should theoretically be unrelated, the researchers expect to see a low correlation between these test results.
If the researchers successfully demonstrate the face validity, criterion validity, and divergent validity of their questionnaire, they have provided compelling evidence that their new measure has high construct validity.