Sampling Methods | Types, Descriptions & Examples
Sampling methods are techniques to select a subset of individuals (the sample) from a larger group (the population). They are key to many research and statistics applications.
Sampling methods are necessary because it’s often difficult—or impossible—to study every individual in a population (imagine trying to survey every adult on Earth!). Instead, researchers focus on a smaller group, called a sample, which allows them to draw conclusions about the larger population.
To make accurate inferences about the population, it’s important to choose a sample that is representative. A representative sample closely reflects the characteristics of the population of interest.
Sampling methods can be categorized as probability or non-probability.
- In probability sampling, every individual in the population has a known or equal chance of being studied, which helps create a more representative sample. Probability sampling includes simple random sampling, systematic sampling, stratified sampling, and cluster sampling.
- In non-probabilistic sampling, individuals are selected based on convenience or other non-random criteria. This makes data collection easier but may introduce bias. Non-probability sampling includes convenience sampling, volunteer sampling, purposive sampling, snowball sampling, and quota sampling.
When writing a report or research paper, it is important to describe the sampling methods you used to select your sample. QuillBot’s free Paraphraser can help you describe your methods as precisely as possible.
The professor could interview every single student on campus, but this would take a very long time. Instead, she selects a sample.
The professor might decide to interview the students in her seminar class. This approach would be quick and easy, but not representative (non-probability sampling).
Alternatively, she could randomly select students from the entire university (probability sampling). This approach would be more representative, but harder to coordinate.
What is a sample?
To understand sampling methods, it is important to review the concepts of population and sample.
When conducting a study, the population is the entire group of individuals that could be included in a study. The population can be defined by any number of characteristics and can be broad or narrow. For example, your population could be all adult humans, all women attending a certain university, or patients receiving treatment for a specific medical condition at a specific hospital.
The sample is a smaller subset of the population that is actually studied. Information obtained from the sample can be used to make educated guesses (or inferences) about the broader population.
A sampling method is the technique used to choose a sample from a population. There are two categories of sampling methods: probability and non-probability.
In this case, the population is all California redwood trees in the park.
The sample is the subset of trees the arborist actually measures.
Sample size
When selecting a sample, the first step is to determine how many individuals you should include. This number is your sample size.
The appropriate sample size depends on the population you are studying and the specific research question you’re trying to answer. There are different statistical techniques to calculate the best sample size.
Sampling frame
A sampling frame is a list of all individuals in the population from which your sample is drawn. For example, it might be a database containing all students attending a university. Not all populations will have a sampling frame, which limits the sampling method you can use.
The sampling frame should ideally include every individual in the population you are studying (and exclude anyone who isn’t part of that population). The sampling method you choose will determine how participants are selected from the sampling frame.
Representative samples
It’s important to choose a representative sample (one that accurately reflects the population you’re trying to learn about). If your sample is biased or doesn’t represent the population well, your results may also be biased and lack external validity, meaning they may not generalize well to the broader population.
To minimize bias and improve external validity it’s important to choose an appropriate sampling method.
The term WEIRD (an acronym that stands for Western, Educated, Industrialized, Rich, and Democratic) describes characteristics frequently associated with undergraduate populations. Because these individuals are overrepresented in research, many studies include samples that do not reflect the full range of human diversity.
Reliance on WEIRD samples can limit how well research generalizes to the broader population. This phenomenon highlights the importance of avoiding sampling bias and considering who was studied when interpreting results.
Probability sampling methods
Probability sampling (or random sampling) is a set of sampling methods where individuals are chosen randomly from a population. The chance of each person being selected can be calculated ahead of time.
Probability sampling methods are good for selecting a representative sample, as they minimize sampling bias. However, these methods are often costly and time-consuming.
There are four main types of probability sampling methods.

Simple random sampling
Simple random sampling is a technique where every individual in the population has an equal chance of being selected. The sample is chosen at random from the sampling frame, similar to drawing names from a hat. Simple random sampling is typically done using computational tools like random number generators.
Simple random sampling is a common sampling method, but it requires a sampling frame, which may not be possible for large or unstudied populations. Because individuals are randomly selected, simple random sampling can also be complicated to conduct.
This process might become difficult if the randomly selected patients cannot be easily contacted (for instance, they might live far away or not have cell phone or internet access).
Systematic sampling
Systematic sampling is similar to simple random sampling, but it follows a more structured selection process. The sampling frame is numbered, and individuals are chosen at regular intervals, beginning from a random starting point.
Like simple random sampling, this technique requires a complete sampling frame. However, there’s also a chance of sampling bias if the sampling frame has hidden patterns or a periodic structure that aligns with the sampling interval.
If there’s a hidden pattern (e.g., every 30th product is made by the same machine), these results might not accurately reflect overall quality.
Stratified sampling
In stratified sampling, the population is divided into subgroups, called strata (singular stratum), based on shared characteristics (e.g., place of residence, income, gender, age). A probability sampling method is then used to select individuals from each stratum.
Unlike simple random or systematic sampling, not every member of the population necessarily has the same chance of being selected—selection probability can differ across strata. Stratified sampling is helpful when you want to make sure you have representation across different groups in your sample.
You could instead use stratified sampling to divide the US population into strata based on state of residence. Then, you would determine a sample size and use an appropriate probability sampling method to sample individuals within each state. This approach would ensure proportional representation of each state.
Cluster sampling
Cluster sampling involves dividing the population into subgroups, called clusters, that each reflect the diversity of the entire population. Instead of sampling some individuals from each subgroup (like in stratified sampling), in cluster sampling a few clusters are randomly selected, and all individuals within these clusters are included in the sample.
Cluster sampling is helpful when your population is spread out over a large area. Rather than sampling individuals across this entire region, you collect data from select clusters, such as schools, factories, or electoral districts.
Though cluster sampling can be less expensive and more practical than other probability sampling methods, there are limitations. The selected clusters might not fully represent the population, and variations in cluster size might make it difficult to control your overall sample size.
Sometimes, it’s infeasible to sample every individual in a cluster. In such cases, you might sample individuals within a cluster using another probability sampling method. This is called multistage sampling: the first step is to select clusters, and the second step is to sample individuals from these clusters.
Non-probability sampling methods
For all the probability sampling methods discussed above, the sample was randomly selected from the population. Every individual had a chance of being selected.
In non-probability sampling, the sample is instead chosen using non-random criteria. Consequently, not every member of the population has a chance of being selected.
Non-probability sampling methods do not require a sampling frame, and they are often much faster, easier, and cheaper than probability sampling. However, there is a higher risk of sampling bias, which limits the strength and generalizability of findings.
Five common types of non-probability sampling are outlined below.
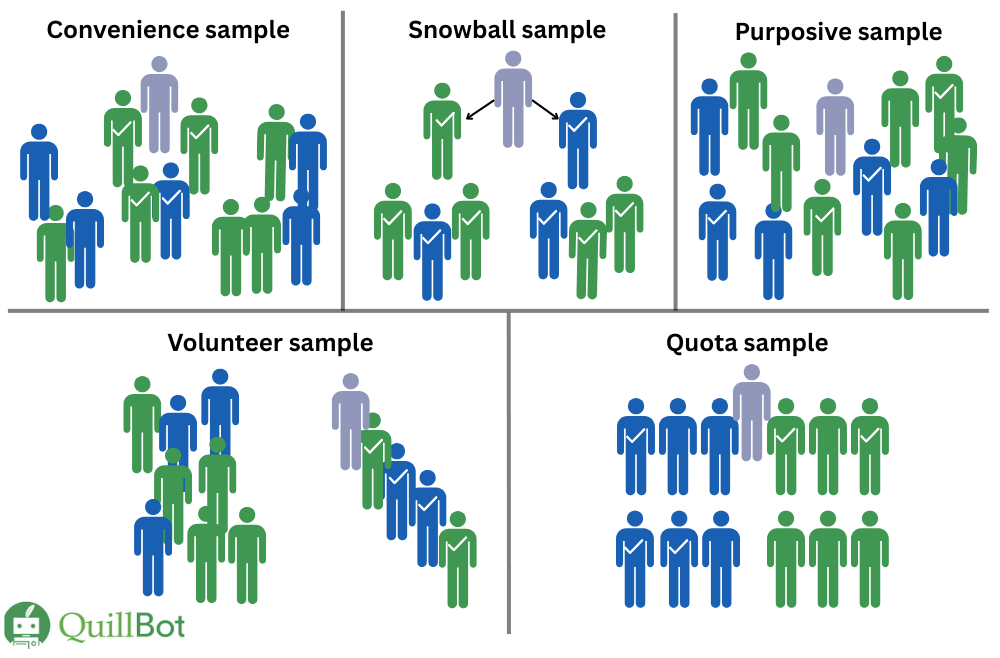
Convenience sampling
Convenience sampling involves sampling individuals who are easiest for the researcher to access. These might be their friends, colleagues, classmates, or people who walk by them on the street.
Convenience sampling is a fast and easy way to collect data, but there’s a high risk of sampling bias, so the results may not generalize. It can be a good data collection technique for early or exploratory research into a topic.
While the data from your colleagues may be informative, if they all work in marketing, their results may not reflect how the general population views ads.
Volunteer sampling
For volunteer sampling (or voluntary response sampling), individuals from the population choose to participate in a study. They may be recruited through social media ads; mailing lists; or posters in places like hospitals, universities, or community centers.
Not every volunteer has to be included in the sample. Researchers may use inclusion criteria (like age, health conditions, or life experiences) to determine who is eligible to participate.
Volunteer sampling is vulnerable to self-selection bias: people who choose to volunteer may differ from those who don’t in important ways, limiting generalizability.
Purposive sampling
Purposive sampling (also known as judgement sampling) requires the researcher to use their knowledge of the population to decide what a representative sample looks like.
Because the researcher is handpicking a sample with desired characteristics, purposive sampling is extremely vulnerable to bias. The researcher may have a preconceived opinion about some phenomenon and select participants that confirm their biases.
Purposive sampling may be helpful for exploratory research, as the researcher can collect data from specific groups or individuals of interest. When conducting purposive sampling, it is important to provide clear rationale for why individuals were included.
One issue with this approach is that the organization might overlook groups they aren’t aware of, like part-time students or students who have never accessed support services.
Snowball sampling
If a population is rare or hard to reach, researchers may use snowball sampling (or network sampling). This technique starts with a small number of participants, who are then asked to refer other people they know who might be eligible to participate.
Like a snowball rolling down a hill, the sample grows as new participants connect the researcher to more people. Though this method can help contact people who would otherwise be hard to access, snowball sampling makes it hard to control how representative your sample is.
Quota sampling
In quota sampling, the population is divided into subgroups called strata based on certain characteristics (e.g, gender, age, socioeconomic status), much like stratified sampling. A predetermined number of individuals (a quota) are then sampled from each stratum using a non-probability sampling method.
Quota sampling allows researchers to control which groups are represented in a sample.
This approach helps ensure that the opinions of different age groups are captured in the results.
Frequently asked questions about sampling methods
- What are random sampling methods?
-
Random sampling (also called probability sampling) is a category of sampling methods used to select a subgroup, or sample, from a larger population. A defining property of random sampling is that all individuals in the population have a known, non-zero chance of being included in the sample.
Random sampling methods include simple random sampling, systematic sampling, stratified sampling, and cluster sampling. All of these methods require a sampling frame (a list of all individuals in the population).
The opposite of random or sampling is non-probability sampling, where not every member of the population has a known chance of being included in the sample.
- What is sampling?
-
Sampling is the process of selecting a subset of individuals (a sample) from a larger population.
Because it’s often not feasible to collect data from every individual in a population, researchers study a sample instead. The goal is to use this sample to make predictions (or inferences) about the broader population.
For example, if you want to study consumer attitudes towards a brand, you might survey a subset of customers rather than every single one.
There are different sampling methods that can be used to select a sample.
- Is simple random sampling probability or nonprobability sampling?
-
Simple random sampling is a common probability sampling technique.
In probability sampling, each individual in the population has the same chance of being selected for the sample. With simple random sampling, individuals are chosen from a list at random, which makes it a probability sampling method.
Other examples of probability sampling are stratified sampling, systematic sampling, and cluster sampling. Examples of nonprobability sampling are convenience sampling, quota sampling, self-selection sampling, snowball sampling, and purposive sampling.
- What is sampling bias?
-
Sampling bias occurs when some individuals in the population are more likely to be included in the population than others. This can limit how well results generalize to the broader population.
Sampling methods like probability sampling help reduce sampling bias because every individual in the population has a known, non-zero chance of being included in the sample. However, it’s difficult to eliminate sampling bias entirely, so results from a sample should always be interpreted with caution.
